
Autonome KI-Labore, wie GPT-5 und Robotik die experimentelle Biologie neu strukturieren
Visualisierung: Konzeptdarstellung eines KI-gesteuerten Closed-Loop-Laborsystems | Redaktionelle Illustration ohne Anspruch auf technische Detailtreue
Die jüngste Kooperation zwischen OpenAI und Ginkgo Bioworks markiert einen strukturellen Wendepunkt in der experimentellen Forschung. Erstmals wurde öffentlich demonstriert, wie ein großes Sprachmodell der neuesten Generation eigenständig reale Biologieexperimente plant, ausführt, auswertet und iterativ optimiert. Dabei agierte das Modell nicht als bloßes Analysewerkzeug, sondern als operativer Bestandteil eines geschlossenen Laborregelkreises.[1][2]
Im Zentrum der Demonstration stand die Optimierung einer zellfreien Proteinsynthese unter Verwendung von GFP als Testsystem. Über sechs Iterationszyklen hinweg wurden mehr als 36.000 experimentelle Varianten automatisiert durchgeführt. Das Resultat war eine Reduktion der spezifischen Produktionskosten um rund 40 Prozent – von etwa 698 US-Dollar pro Gramm auf rund 422 US-Dollar.[1][3]
Entscheidend ist weniger die absolute Zahl als die Struktur des Prozesses. Das Sprachmodell generierte eigenständig neue Reagenzienmischungen, validierte diese gegen definierte Laborregeln, ließ sie über eine modulare Roboterinfrastruktur ausführen und analysierte anschließend die resultierenden Messdaten. Hypothese, Ausführung und Evaluation bildeten damit erstmals eine vollständig integrierte KI-Robotik-Schleife.[2][4]
Die Visualisierung verdichtet diesen Paradigmenwechsel bewusst zu einem konzeptionellen Bild. Sie zeigt kein einzelnes Gerät, sondern eine Architektur: Ein Modell, das über digitale Schnittstellen mit Laborautomatisierung kommuniziert, physische Prozesse auslöst und deren Ergebnisse in Echtzeit in neue Entscheidungslogik überführt. Forschung wird dadurch nicht nur beschleunigt, sondern strukturell reorganisiert.
Demonstration des autonomen Closed-Loop-Labors
Die im Februar 2026 präsentierte Demonstration basierte auf einem geschlossenen Experimentierkreislauf. GPT-5 erhielt Zugriff auf eine kontrollierte Rechenumgebung mit Internetzugang, wissenschaftlicher Literatur und Python-Analysewerkzeugen. Auf Basis historischer Daten, aktueller Preprints und experimenteller Rückmeldungen entwarf das Modell neue 384-Well-Plattenlayouts für die zellfreie Proteinsynthese.[5][6]
Insgesamt wurden über 580 Mikroplatten verarbeitet, was knapp 150.000 Datenpunkte generierte. Jede Iteration bestand aus der Generierung neuer Mischungsverhältnisse, deren robotischer Ausführung in Ginkgos Cloud-Laborinfrastruktur sowie der anschließenden Messung der Proteinexpression mittels Fluoreszenzdetektion.[1][7]
Die physische Umsetzung erfolgte über sogenannte Reconfigurable Automation Carts (RACs). Diese modularen Einheiten kombinieren Pipettierroboter, Inkubationsmodule und Plattenlesegeräte, die automatisch über Fördersysteme miteinander verbunden sind. Dadurch entsteht ein durchgängiger Laborworkflow ohne manuelle Intervention.[4][8]
Zwischen Modell und Laborhardware fungierte ein Validierungsschema auf Basis von Pydantic. Jede von GPT-5 erzeugte Versuchsplanung wurde formal überprüft, um unzulässige Konzentrationen, inkonsistente Plattenlayouts oder nicht realisierbare Parameterkombinationen auszuschließen. Erst nach erfolgreicher Validierung wurde das Experiment physisch ausgeführt.[6][9]
Der geschlossene Regelkreis bestand somit aus vier Schritten:
- Generierung eines Versuchsdesigns durch GPT-5
- Formale Validierung des Designs
- Robotische Ausführung über Catalyst und RAC-Module
- Rückführung der Messdaten an das Modell zur Optimierung
Dieser Prozess wiederholte sich über sechs Iterationen hinweg, wobei das Modell zunehmend engere Parameterregionen identifizierte, die zu höherer Effizienz bei geringeren Kosten führten.[1][3]
Closed-Loop-Architektur: Sprachmodell, Validierung, Robotik und Messsysteme im kontinuierlichen Regelkreis
Illustration: Redaktionelle Konzeptdarstellung eines autonomen KI-Laborsystems
Der entscheidende Unterschied zu klassischen High-Throughput-Laboren liegt nicht allein in der Automatisierung, sondern in der Entscheidungsintegration. Während herkömmliche Systeme vorgegebene Parameterreihen abarbeiten, bewertet das KI-System Ergebnisse eigenständig und passt seine Strategie dynamisch an. Das Labor verhält sich damit funktional wie ein lernendes System.
Im nächsten Kapitel wird die technische Architektur dieser Pipeline im Detail analysiert.
Technische Architektur – KI, Validierung und modulare Robotik
Das autonome Laborsystem basiert auf einer mehrschichtigen Architektur, die kognitive KI-Entscheidungsprozesse mit physischer Laborautomatisierung verbindet. Im Zentrum steht das Sprachmodell GPT-5 als strategische Steuerinstanz. Es übernimmt Hypothesenbildung, Parameteroptimierung, Datenanalyse und die Planung nachfolgender Experimente.[2][5]
GPT-5 operierte dabei nicht isoliert, sondern in einer kontrollierten Agenten-Umgebung mit Zugriff auf wissenschaftliche Literatur, Preprints sowie eine Python-basierte Analyseumgebung. Dadurch konnte das Modell sowohl externe Fachinformationen einbeziehen als auch statistische Auswertungen eigenständig durchführen. In den veröffentlichten Berichten wird beschrieben, dass das Modell beispielsweise Standardkurven interpolierte, Ausreißer identifizierte und Parametercluster analysierte, bevor es neue Versuchsreihen entwarf.[6][10]
Die Schnittstelle zwischen Modell und Laborhardware erfolgte über ein strukturiertes JSON-Schema, das mithilfe von Pydantic definiert wurde. Dieses Schema beschrieb jede 384-Well-Platte in maschinenlesbarer Form, inklusive Reagenzien, Konzentrationen, Kontrollproben und Volumina. Ziel war es, Halluzinationen oder physikalisch unmögliche Kombinationen algorithmisch zu verhindern.[6][9]
Nur validierte Designs wurden an die Automatisierungsschicht weitergeleitet. Diese Schicht wird bei Ginkgo durch die Software „Catalyst“ realisiert, die als Orchestrator fungiert. Catalyst übersetzt die JSON-Experimente in konkrete Steuerprotokolle für die Laborgeräte und koordiniert die Abläufe zwischen Pipettierrobotern, Inkubatoren und Messinstrumenten.[4][8]
Die physische Ebene bilden die sogenannten Reconfigurable Automation Carts (RACs). Jede Einheit enthält einen Roboterarm sowie ein spezifisches Laborgerät. Mehrere RACs können modular verbunden werden, sodass komplexe Arbeitsketten entstehen. Mikroplatten werden automatisiert zwischen den Modulen transportiert, ohne dass menschliches Eingreifen erforderlich ist.[8]
Modulare RAC-Architektur: Roboterarme und Laborgeräte als kombinierbare Automatisierungseinheiten
Illustration: Konzeptdarstellung einer modularen Laborautomatisierungsplattform
Nach Abschluss der Inkubationsphase wurden die Reaktionsresultate mittels Fluoreszenz- oder Spektralmessung quantifiziert. Diese Rohdaten wurden gemeinsam mit Metadaten wie Inkubationsdauer, Gerätezustand und Plattenlayout wieder an GPT-5 übermittelt. Das Modell analysierte die Resultate und leitete daraus die nächste Iteration ab.[7][10]
Die Architektur lässt sich funktional in folgende Ebenen gliedern:
- Kognitive Ebene → GPT-5 als Hypothesen- und Optimierungsinstanz
- Validierungsebene → Pydantic-Schema zur Sicherstellung laborfähiger Designs
- Orchestrierungsebene → Catalyst als Workflow-Koordinator
- Hardwareebene → RAC-Module für robotische Ausführung
- Mess- und Feedbackebene → Sensorik und Datenrückführung
Der strukturelle Mehrwert dieser Architektur liegt in der engen Kopplung aller Ebenen. Während klassische Laborautomatisierung vorgegebene Protokolle ausführt, entscheidet hier ein lernendes Modell, welche Protokolle als nächstes sinnvoll sind. Die physische Infrastruktur wird damit zur ausführenden Instanz einer datengetriebenen Optimierungslogik.[2][4]
Besonders relevant ist dabei die Entkopplung von kognitiver und physischer Ebene. Das Modell selbst führt keinen Robotercode aus, sondern definiert ausschließlich experimentelle Parameter. Die sicherheitskritische Umsetzung bleibt in der kontrollierten Automatisierungsumgebung verankert. Diese Trennung reduziert das Risiko unkontrollierter Systemzustände und erhöht die Auditierbarkeit.[9]
Im nächsten Kapitel werden konkrete Implementierungsdetails sowie Software- und Infrastrukturfragen analysiert.
Implementierungsdetails, Software Stack, Schnittstellen und Sicherheitsmechanismen
Die Demonstration des autonomen Labors beruhte nicht allein auf der Leistungsfähigkeit des Sprachmodells, sondern auf einer präzise abgestimmten Systemintegration. Der technische Kern war eine Pipeline, die KI Agentenlogik, strukturierte Validierung, Workflow Orchestrierung und physische Laborautomatisierung in einer kontrollierten Umgebung zusammenführt.[2][6]
Auf Seiten von OpenAI wurde GPT 5 in einer Agenten Umgebung betrieben, die Zugriff auf Python basierte Analysewerkzeuge, Webrecherche in wissenschaftlichen Quellen sowie persistente Datenspeicher für Messdaten ermöglichte. Dadurch konnte das Modell Literaturkontext mit numerischer Auswertung verbinden und nach jeder Datenlieferung unmittelbar neue Versuchspläne ableiten. In den beschriebenen Abläufen wurden unter anderem Datenbereinigung, Ausreißererkennung und modellgestützte Interpolation genutzt, bevor neue Parameterregionen getestet wurden.[5][10]
Die Interaktion zwischen KI und Labor erfolgte über strukturierte JSON Definitionen. Jede Experimentbeschreibung codierte ein vollständiges 384 Well Plattenlayout mit Reagenzien, Konzentrationen, Volumina, Kontrollen und Verdünnungen. Diese Form der maschinenlesbaren Spezifikation ist entscheidend, weil sie das Modell auf die Rolle der Parameterentscheidung begrenzt und die Ausführung konsequent in der Automatisierungsumgebung verankert.[6][9]
Ein zentrales Sicherheitsinstrument war das Pydantic Validierungsschema. Es überprüfte jedes KI generierte Design auf Laborfähigkeit, etwa zulässige Volumenbereiche, konsistente Kontrollen und regelkonforme Kombinationen. Ungültige oder unpraktikable Vorschläge wurden automatisiert zurückgewiesen, bevor sie die Hardware erreichen konnten. Damit wurde ein kritischer Risikopfad adressiert, nämlich die Überführung fehlerhafter Modellvorschläge in reale Flüssighandling Abläufe.[9]
Nach der Validierung übernahm die Catalyst Software die Orchestrierung. Catalyst transformierte die JSON Protokolle in konkrete Geräteoperationen, koordinierte Pipettierabläufe, Inkubationsschritte und Messroutinen und steuerte den Plattentransport zwischen den modularen RAC Einheiten. Gleichzeitig erfasste das System Protokolldaten und Metadaten für spätere Nachvollziehbarkeit und Auditierbarkeit.[4][8]
Implementierungslogik, strukturierte Schnittstelle zwischen Modell, Validierung, Orchestrierung und modularer Laborhardware
Illustration: Redaktionelle Systemdarstellung der KI zu Labor Pipeline
- Strukturierte Schnittstelle → Experimente werden als JSON beschrieben, nicht als Robotercode
- Formale Validierung → Pydantic filtert unzulässige Designs, bevor sie ausgeführt werden
- Orchestrierte Ausführung → Catalyst koordiniert RAC Module, Messung und Datenrückführung
Wichtig ist auch die zeitliche Architektur. Biologische Inkubationsphasen dauern viele Stunden, weshalb das System keine harte Echtzeit im Millisekundenbereich benötigt. Entscheidend ist vielmehr eine zuverlässige asynchrone Abfolge: Design, Ausführung, Messung, Rückführung, nächste Iteration. In dieser Logik wird Forschung nicht schneller durch Reaktionszeit, sondern durch geschlossene Automatisierung und schnelle Entscheidungsiteration.[1][7]
Sicherheitsseitig blieb menschliche Aufsicht weiterhin Teil des Betriebs, vor allem für Reagenzienmanagement, Wartung und Notabschaltung. Zusätzlich wurden die Entscheidungen des Modells protokolliert. GPT 5 erzeugte erklärende Notizen, die den jeweiligen Optimierungsschritt und die zugrunde liegende Begründung dokumentierten, was spätere Audits und Reproduzierbarkeit unterstützt.[9]
Im nächsten Kapitel wird der wissenschaftliche Kontext eingeordnet und gezeigt, wie diese Demonstration an Self Driving Lab Forschung anknüpft und welche Unterschiede sich aus der Einbettung eines großen Sprachmodells ergeben.
Wissenschaftlicher Kontext, Self Driving Labs und die Rolle großer Sprachmodelle
Autonome Labore sind kein isoliertes Einzelereignis, sondern Teil eines wachsenden Forschungsfeldes, das unter Begriffen wie Self Driving Labs oder Closed Loop Experimentation diskutiert wird. In Chemie, Materialwissenschaft und Biotechnologie werden seit mehreren Jahren robotergestützte Plattformen mit maschinellem Lernen kombiniert, um Optimierungsaufgaben automatisiert zu lösen.[11][12]
Typischerweise basieren diese Systeme auf Bayes’scher Optimierung oder anderen aktiven Lernverfahren. Sie generieren neue Parameterkombinationen, führen Experimente automatisiert durch und nutzen die Ergebnisse, um den Suchraum schrittweise einzugrenzen. Der Fokus liegt meist auf klar definierten Zielgrößen wie Ausbeute, Stabilität oder Reaktionsgeschwindigkeit.[11][13]
Die OpenAI × Ginkgo Demonstration erweitert dieses Paradigma in zweierlei Hinsicht. Erstens wird kein spezialisiertes Optimierungsmodell verwendet, sondern ein großes Sprachmodell, das ursprünglich für Textverarbeitung trainiert wurde. Zweitens übernimmt dieses Modell nicht nur die Parameteroptimierung, sondern auch Kontextintegration, Literaturrecherche und experimentelle Begründung. Damit verschiebt sich die Rolle der KI von einem reinen Optimierungswerkzeug zu einer generalistischen Entscheidungsinstanz.[2][5]
Frühere Self Driving Lab Projekte operierten häufig auf Labor Prototyp Niveau oder in eng abgegrenzten Forschungsumgebungen. Hier hingegen wurde eine skalierte Cloud Labor Infrastruktur genutzt, in der über 36.000 Varianten real ausgeführt wurden. Der Unterschied liegt nicht nur im Umfang, sondern in der Integrationstiefe zwischen Modell, Validierung und physischer Robotik.[1][7]
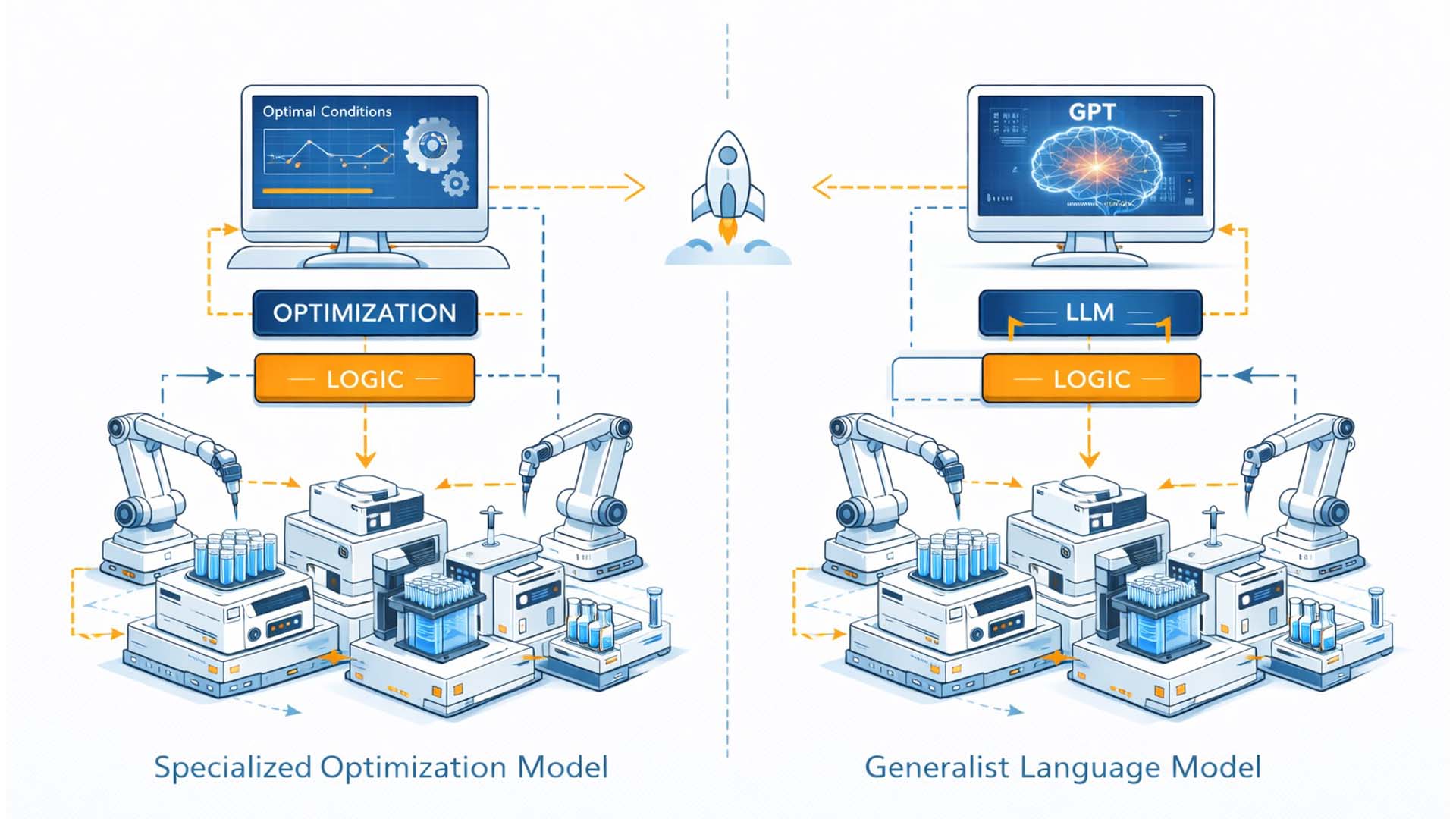
Vom spezialisierten Optimierungsmodell zum generalistischen Sprachmodell als Entscheidungsinstanz im autonomen Labor
Illustration: Redaktionelle Gegenüberstellung klassischer SDL Architektur und LLM integrierter Laborsteuerung
- Klassische SDL Systeme → Spezialisierte Optimierungsalgorithmen mit klar definierten Zielmetriken
- LLM basierte Systeme → Kontextintegration, Literaturzugriff und experimentelle Begründung
- Skalierte Infrastruktur → Cloud Labor mit tausenden real ausgeführten Varianten
Im wissenschaftlichen Diskurs wird zunehmend diskutiert, wie solche Plattformen Forschung demokratisieren könnten. Cloudbasierte Labore erlauben es theoretisch, Experimente remote zu definieren und automatisiert auszuführen. Canty et al. beschreiben in diesem Zusammenhang, dass digitale Protokolle direkt in physische Laboroperationen übersetzt werden können, wodurch der Transfer von Hypothese zu Test erheblich beschleunigt wird.[12][14]
Gleichzeitig werfen Sprachmodelle neue Fragen auf. Während klassische Optimierer auf mathematisch klar definierte Zielfunktionen beschränkt sind, operieren große Sprachmodelle probabilistisch und kontextsensitiv. Ihre Stärke liegt in der Generalisierung, ihre Schwäche potenziell in mangelnder formaler Garantierbarkeit. Die Integration eines Validierungsschemas wie Pydantic wird damit nicht nur zu einer technischen, sondern zu einer epistemischen Notwendigkeit.[6][9]
Ein weiterer Unterschied betrifft die Interpretierbarkeit. In der Demonstration erzeugte GPT 5 erklärende Labornotizen, die seine Optimierungsstrategie dokumentierten. Das ist wissenschaftlich relevant, weil es eine Brücke zwischen Black Box Modell und nachvollziehbarer Experimentplanung schlägt. Dennoch bleibt offen, in welchem Maß solche Begründungen tatsächlich kausal oder lediglich plausibel formuliert sind.[9][11]
Im nächsten Kapitel werden konkrete Anwendungen und wirtschaftliche Implikationen dieser Technologie analysiert, insbesondere mit Blick auf Kostensenkung, Beschleunigung von F und E Prozessen und neue Geschäftsmodelle.
Anwendungen und Nutzen, Beschleunigung biologischer Forschung durch KI gesteuerte Closed Loop Systeme
Die ökonomische und wissenschaftliche Relevanz der Demonstration zeigt sich vor allem in der erreichten Effizienzsteigerung. Innerhalb von sechs Iterationszyklen konnte die spezifische Produktionskostenstruktur der zellfreien Proteinsynthese um rund 40 Prozent reduziert werden. Die Kosten pro Gramm Protein sanken von etwa 698 US Dollar auf rund 422 US Dollar.[1][3]
Diese Reduktion ist kein isolierter Effekt einzelner Parameteranpassungen, sondern Resultat systematischer, datengetriebener Exploration. Das Modell testete nicht wahllos Kombinationen, sondern lernte iterativ, welche Konzentrationsverhältnisse und Reagenzienmischungen besonders vielversprechend waren. Dadurch verdichtete sich der Suchraum schrittweise auf ökonomisch optimale Regionen.[5][7]
Für industrielle Anwendungen bedeutet das eine fundamentale Verschiebung der Forschungslogik. Klassische Laboroptimierung ist stark sequenziell und personalintensiv. Hypothesen werden formuliert, getestet, manuell ausgewertet und anschließend angepasst. Ein Closed Loop System hingegen kann Tag und Nacht automatisiert arbeiten, wodurch sich die Zeit bis zur Identifikation optimaler Parameter signifikant verkürzt.[11][12]
Besonders relevant sind folgende Anwendungsfelder:
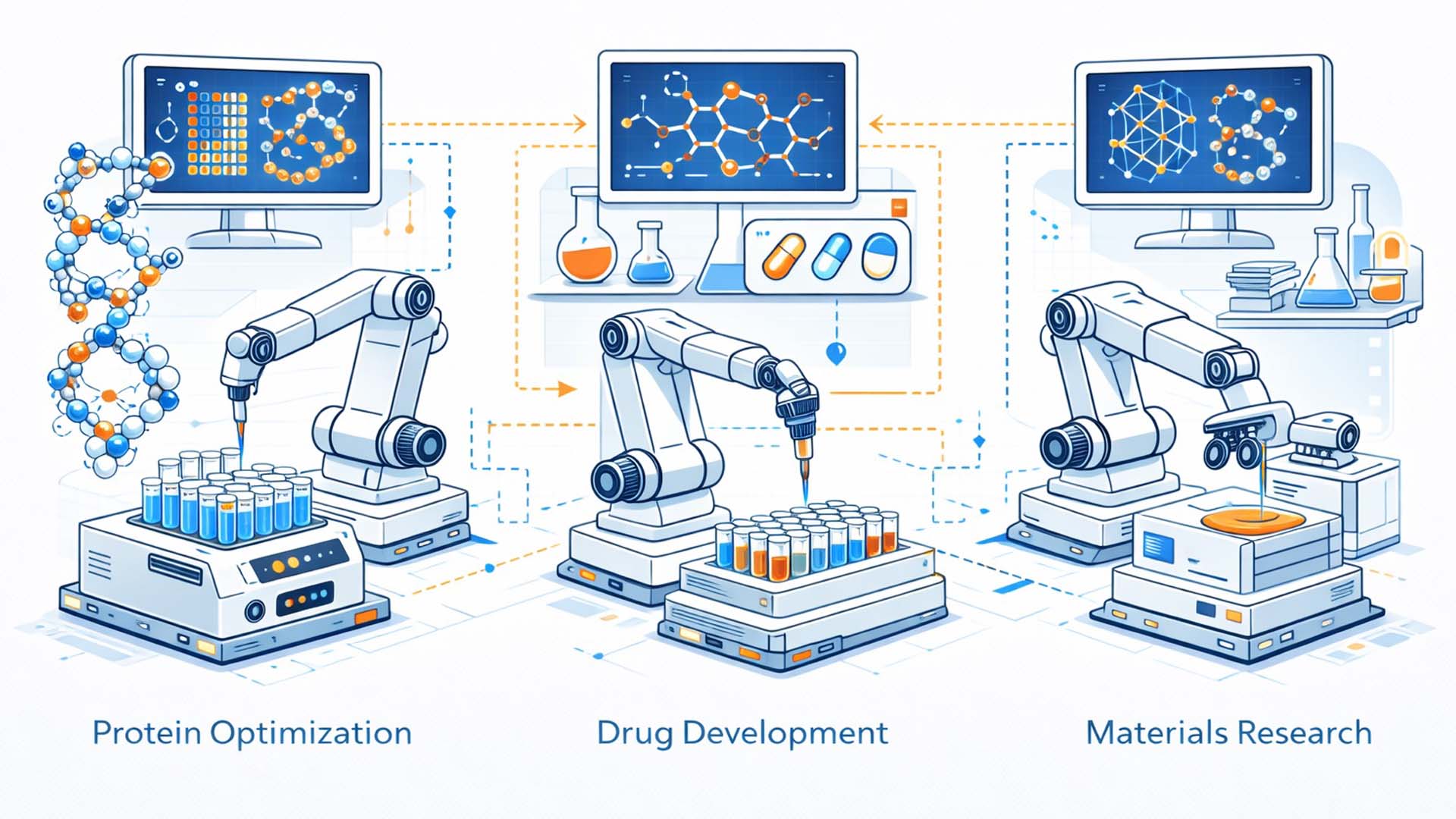
Anwendungsspektrum, von Proteinoptimierung über Wirkstoffentwicklung bis Materialforschung
Illustration: Redaktionelle Visualisierung möglicher Einsatzbereiche autonomer Laborsysteme
- Biopharma Entwicklung → Optimierung von Expressionssystemen, Formulierungen und Produktionsbedingungen
- Enzym Engineering → Systematische Suche nach stabileren oder effizienteren Varianten
- Material und Katalysatorforschung → Automatisierte Exploration komplexer Parameterlandschaften
Im Bereich der Medikamentenentwicklung könnten Tausende experimenteller Varianten automatisiert getestet werden, um stabile Proteinstrukturen, Antikörper oder Impfstoffkomponenten zu optimieren. Ähnlich verhält es sich in der Materialforschung, in der Zusammensetzungen von Katalysatoren oder Batteriematerialien gegen definierte Leistungsmetriken getestet werden können.[11][13]
Ein weiterer Nutzen liegt in der Skalierung von Wissen. Da das Sprachmodell Literatur einbezieht und experimentelle Resultate mit externen Erkenntnissen kombiniert, entsteht eine hybride Wissensverarbeitung. Forschung wird dadurch nicht nur schneller, sondern potenziell breiter kontextualisiert. Das System kann beispielsweise aktuelle Preprints berücksichtigen und unmittelbar experimentell prüfen, ob dort beschriebene Parameterbereiche reproduzierbar sind.[5][6]
Ökonomisch eröffnen sich neue Geschäftsmodelle. KI optimierte Reagenzien oder Produktionsmischungen können direkt vermarktet werden. Ebenso denkbar sind kombinierte Angebote aus KI Agenten und Cloud Labor Infrastruktur, bei denen Unternehmen Optimierungsaufgaben auslagern, ohne selbst in vollständige Robotik investieren zu müssen.[1]
Langfristig verschiebt sich damit die Kostenstruktur von Forschung und Entwicklung. Statt hohe Budgets in manuelle Iterationen zu investieren, kann ein signifikanter Anteil der Optimierungsarbeit automatisiert erfolgen. Das führt zu mehr experimenteller Evidenz pro investiertem Dollar und verkürzt Entwicklungszyklen signifikant.
Im nächsten Kapitel werden die damit verbundenen Risiken, Sicherheitsfragen und Governance Herausforderungen analysiert.
Risiken und Governance, Biosicherheit, Fehlerrisiken und regulatorische Anforderungen
So vielversprechend autonome KI gesteuerte Labore sind, so komplex sind die damit verbundenen Risiken. Die Integration eines großen Sprachmodells in einen physischen Experimentierkreislauf verschiebt Verantwortungsebenen und eröffnet neue Angriffsflächen. Neben technischen Fehlerrisiken treten Fragen der Biosicherheit, Cybersecurity und regulatorischen Einordnung in den Vordergrund.[15][16]
Ein zentrales Thema ist die Biosicherheit. In der Demonstration wurde mit zellfreier Proteinsynthese gearbeitet, also ohne lebende Organismen. Dennoch zeigt das Prinzip, dass KI Systeme potenziell auch komplexere biologische Prozesse steuern könnten. Ohne geeignete Kontrollmechanismen bestünde das Risiko, dass gefährliche Kombinationen von Reagenzien oder genetischem Material erzeugt werden. Daher ist eine strikte Begrenzung des zugänglichen Reagenzienkatalogs und eine mehrstufige Validierung unerlässlich.[15][17]
Ein weiteres Risiko betrifft die Zuverlässigkeit des Sprachmodells selbst. Große Sprachmodelle arbeiten probabilistisch und können fehlerhafte oder nicht vollständig konsistente Vorschläge generieren. Das in Kapitel drei beschriebene Validierungsschema reduziert dieses Risiko erheblich, ersetzt jedoch keine umfassende Systemaufsicht. Besonders bei skalierter Anwendung muss sichergestellt werden, dass systematische Fehlinterpretationen frühzeitig erkannt werden.[6][9]
Cybersecurity ist eine zusätzliche Dimension. Da das Modell mit Literaturquellen und digitalen Schnittstellen interagiert, besteht theoretisch die Gefahr von Manipulation durch externe Datenquellen oder gezielte Eingaben. Eine isolierte Infrastruktur, Zugriffskontrollen und detailliertes Logging sind daher zentrale Bestandteile eines verantwortungsvollen Systemdesigns.[16]
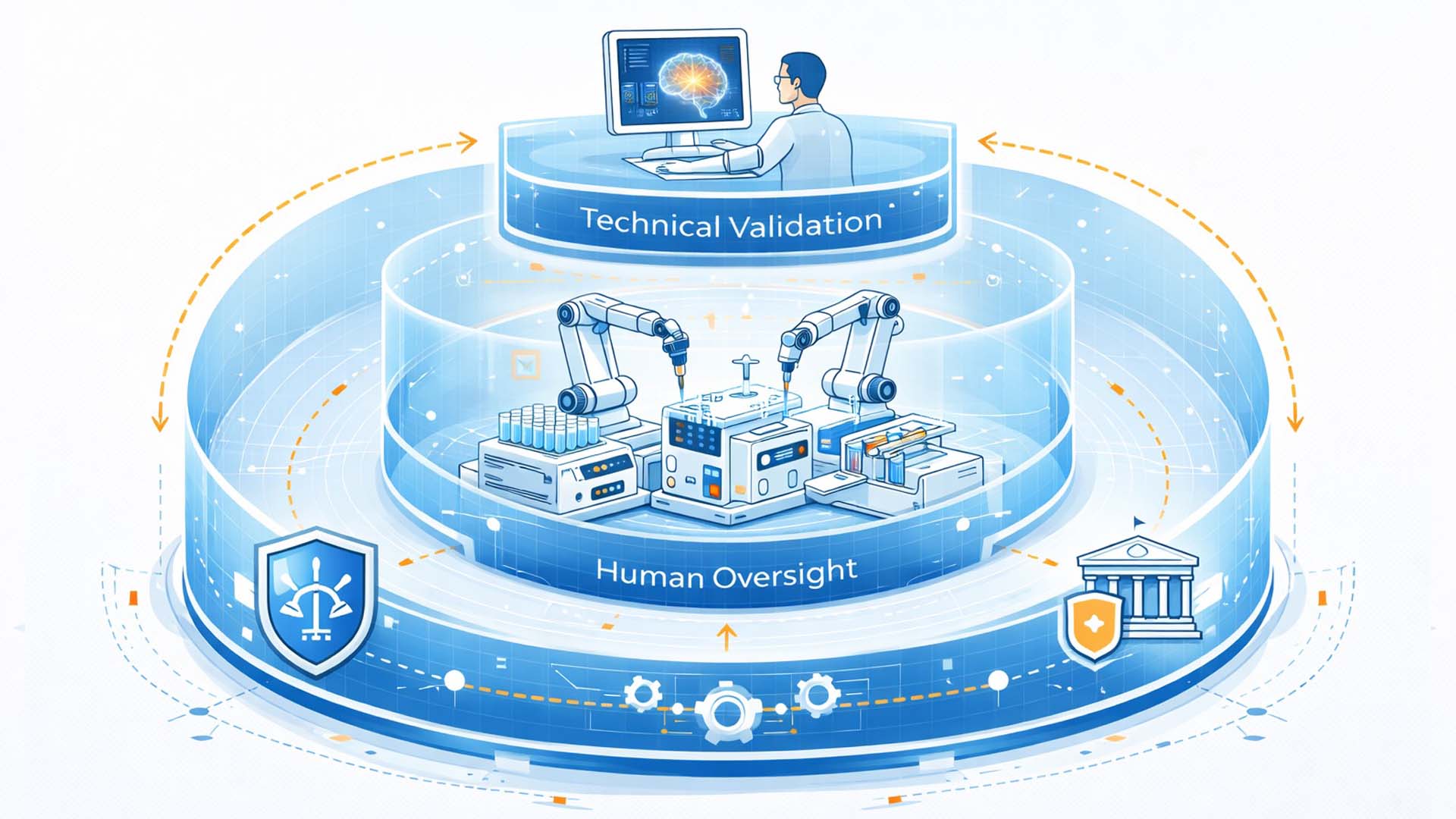
Mehrschichtige Governance Struktur, technische Validierung, menschliche Aufsicht und regulatorischer Rahmen
Illustration: Redaktionelle Darstellung von Sicherheits und Governance Ebenen in autonomen Laborsystemen
- Biosicherheitskontrolle → Begrenzte Reagenzienkataloge und formale Validierung aller Designs
- Modellaufsicht → Protokollierung, Auditierbarkeit und menschliche Review Instanzen
- Cybersecurity → Isolierte Netzwerke, Zugriffsbeschränkung und Manipulationsschutz
Regulatorisch bewegen sich autonome Labore an der Schnittstelle zwischen Biotechnologie, Medizinrecht und KI Regulierung. In der Europäischen Union würde ein derartiges System voraussichtlich unter Hochrisiko KI fallen, sofern es in sicherheitskritischen oder medizinischen Kontexten eingesetzt wird. Gleichzeitig greifen bestehende Biosicherheits und Gentechnikregelungen, die bislang primär auf menschliche Bediener ausgerichtet sind.[16][18]
Ein weiteres Governance Thema ist die Haftungsfrage. Wenn ein KI System experimentelle Entscheidungen trifft, stellt sich die Frage nach Verantwortung bei Fehlresultaten oder Schäden. Ist der Betreiber des Labors verantwortlich, der KI Anbieter oder der Entwickler der Validierungsschnittstelle. Diese Fragen sind juristisch bislang nur teilweise geklärt und erfordern neue regulatorische Leitlinien.[15]
Positiv hervorzuheben ist die in der Demonstration umgesetzte Auditierbarkeit. GPT 5 dokumentierte seine Entscheidungslogik in erklärenden Notizen. Zusätzlich wurden Validierungscode und Teile der Infrastruktur offen zugänglich gemacht. Diese Transparenz ist ein wichtiger Schritt, um Vertrauen in autonome Systeme aufzubauen.[9]
Langfristig wird entscheidend sein, Governance nicht als nachgelagerte Regulierung zu verstehen, sondern als integralen Bestandteil der Architektur. Nur wenn Sicherheitsmechanismen, menschliche Aufsicht und technische Begrenzungen von Anfang an eingebettet sind, können autonome Labore gesellschaftlich akzeptiert und industriell skaliert werden.
Im nächsten Kapitel werden die ökonomischen und organisatorischen Auswirkungen dieser Technologie analysiert.
Ökonomische und organisatorische Auswirkungen, neue Geschäftsmodelle und veränderte Rollenbilder
Die Einführung autonomer KI gesteuerter Labore wirkt nicht nur technologisch disruptiv, sondern verändert auch wirtschaftliche und organisatorische Strukturen in Forschung und Industrie. Wenn ein Sprachmodell wie GPT 5 experimentelle Designs generiert, Kosten optimiert und iterativ lernt, verschiebt sich der Fokus von manueller Durchführung hin zu strategischer Steuerung und Dateninterpretation.[9][14]
Ein zentrales ökonomisches Argument ist die Effizienzsteigerung. In der Demonstration konnte die zellfreie Proteinsynthese um rund 40 Prozent kostengünstiger gestaltet werden.[9] Diese Einsparung entsteht nicht durch billigere Rohstoffe allein, sondern durch gezielte Parameteroptimierung, geringere Fehlversuche und beschleunigte Lernzyklen. In klassischen Laborumgebungen würden vergleichbare Optimierungen Monate oder Jahre dauern. Ein autonomes System kann dagegen rund um die Uhr Versuchsreihen ausführen und auf Basis realer Daten sofort nachjustieren.
Damit entstehen neue Geschäftsmodelle. Cloudbasierte Labordienstleistungen, KI optimierte Reagenzien oder modulare Automatisierungsplattformen könnten sich als eigenständige Marktsegmente etablieren. Unternehmen, die sowohl KI Kompetenzen als auch automatisierte Infrastruktur besitzen, gewinnen strategische Vorteile. Gleichzeitig können kleinere Forschungsteams über externe Plattformen auf leistungsfähige Laborressourcen zugreifen, ohne eigene Hochtechnologie betreiben zu müssen.[12][14]
Organisatorisch verändert sich die Rollenverteilung. Routinearbeiten wie Pipettieren oder manuelles Screening treten in den Hintergrund. Stattdessen gewinnen Kompetenzen in Datenanalyse, Automatisierungsarchitektur und KI Steuerung an Bedeutung. Forscher formulieren Hypothesen und Zielmetriken, während KI Systeme große Parameterlandschaften explorieren. Techniker überwachen Infrastruktur, Schnittstellen und Sicherheitsmechanismen.[13][14]

Transformation von Laborarbeit, von manueller Durchführung zu datengetriebener Systemsteuerung
Illustration: Redaktionelle Visualisierung organisatorischer Veränderungen durch autonome KI Laborsysteme
- Kostensenkung → Reduzierte Fehlversuche und beschleunigte Optimierungszyklen
- Neue Geschäftsmodelle → KI optimierte Reagenzien und Lab as a Service Plattformen
- Rollenwandel → Mehr Datenkompetenz, weniger manuelle Routinearbeit
Auch die Innovationsdynamik verändert sich. Wenn Closed Loop Systeme kontinuierlich lernen, steigt die Zahl möglicher Experimente drastisch. Forschung wird iterativer, datenintensiver und stärker modellbasiert. Entscheidungen beruhen weniger auf isolierten Einzelversuchen, sondern auf systematischen Explorationsstrategien. Das kann die Time to Market in Bereichen wie Biopharma, Materialentwicklung oder Enzymdesign deutlich verkürzen.[14]
Gleichzeitig entstehen Investitionsanforderungen. Der Aufbau autonomer Laborplattformen erfordert erhebliche Anfangskosten für Robotik, Softwareintegration und KI Infrastruktur. Langfristig jedoch könnten Skaleneffekte entstehen, bei denen große Experimentmengen zu sinkenden Kosten pro Erkenntnis führen.
Ökonomisch betrachtet markieren autonome Labore daher nicht nur eine Effizienzsteigerung, sondern einen strukturellen Wandel in der Wissensproduktion. Forschung wird zunehmend als orchestrierter Datenprozess verstanden, in dem KI, Robotik und menschliche Expertise eng verzahnt sind.
Im folgenden Kapitel werden Skalierungsfragen und langfristige Implementierungshürden analysiert.
Video, Closed Loop KI Labor im Realbetrieb
Am 11. Februar veröffentlichte OpenAI die Demonstration „GPT-5 × Ginkgo Bioworks Autonomous Laboratory“. Das Video dokumentiert erstmals sichtbar eine vollständig integrierte Closed Loop Laborarchitektur, in der ein großes Sprachmodell reale Experimente entwirft, robotisch ausführen lässt und auf Basis der Messdaten weiter optimiert. Die folgende Einordnung erfolgt aus analytischer Perspektive durch Ulrich Buckenlei.
Im Video wird eine strukturelle Verschiebung deutlich. Künstliche Intelligenz ist nicht länger ein Analysewerkzeug am Rand des Systems, sondern Teil der operativen Infrastruktur. Das Modell generiert Versuchsdesigns, die automatisierte Laborplattform setzt sie physisch um, die Ergebnisse fließen zurück und bilden die Grundlage für die nächste Iteration. Entscheidungslogik, Ausführung und Optimierung sind in einem kontinuierlichen Regelkreis verbunden.
Besonders relevant ist die ökonomische Dimension. Die demonstrierte Architektur reduzierte die Kosten der Proteinproduktion um rund 40 Prozent. Das ist kein inkrementeller Fortschritt, sondern ein struktureller Produktivitätssprung. Autonome Laborsysteme erscheinen damit als erste sichtbare Ausprägung einer AI nativen industriellen Infrastruktur.
GPT-5 gesteuerte Closed Loop Experimentarchitektur im Ginkgo Autonomous Lab
Videoquelle: OpenAI | GPT-5 × Ginkgo Bioworks Autonomous Laboratory Demonstration | Analyse: Ulrich Buckenlei
Mit dieser Demonstration wird der Übergang vom Assistenzsystem zur infrastrukturellen KI sichtbar. Forschung wird nicht nur unterstützt, sondern strukturell neu organisiert.
Quellen und Referenzen
- OpenAI, “Introducing GPT-5 for Scientific Discovery and Autonomous Labs”, Blogbeitrag zur Closed-Loop-Demonstration mit Ginkgo Bioworks, 2026. [1]
- Ginkgo Bioworks, Pressemitteilung zur Kooperation mit OpenAI und zur 40 % Kostensenkung bei zellfreier Proteinsynthese, 2026. [9]
- BioRxiv Preprint, Technischer Bericht zur autonomen Optimierung von CFPS-Reaktionen durch GPT-5 in einer geschlossenen Feedbackschleife, 2026. [3]
- Nature Communications, Canty et al., “Self-Driving Laboratories and Cloud-Integrated Experimentation Platforms”, 2025. [14]
- Royal Society Open Science, Tobias & Wahab, “Self-Driving Labs: Governance, Patent and Biosecurity Considerations”, 2025. [13]
- Pydantic Documentation, Validierung strukturierter Datenschemata für maschinenlesbare Laborprotokolle, Python Foundation. [6]
- Ginkgo Bioworks Catalyst Platform, Technische Beschreibung der Orchestrierungssoftware für modulare Laborautomatisierung, 2025. [19]
- SLAS Technology, Publikationen zu Reconfigurable Automation Carts (RAC) und modularer Laborrobotik, 2024–2026. [32]
- OpenAI × Ginkgo Demonstration Data Release, Zusammenfassung der Iterationen, 36.000 Versuchsvarianten und Kostensenkungsmetriken. [9]
- US Department of Energy, Genesis Mission – Integration von Supercomputing, KI und autonomen Laboren, 2025. [12]
- Council on Strategic Risks, Empfehlungen zu Biosecurity und KI-gestützter Biotechnologie, 2025. [15]
- European Union AI Act, Regulatorischer Rahmen für Hochrisiko-KI-Systeme in sicherheitskritischen Anwendungen, 2024. [16]
- ENISA, Leitlinien zur Cybersecurity in KI-gestützten industriellen Systemen, 2024. [17]
- Gend.co, Analyse zu Closed-Loop-Laborplattformen und KI-optimierter Forschung, 2026. [22]
- Open Source Release – Validation Schema, Veröffentlichung des experimentellen JSON-Validierungsschemas durch Ginkgo Bioworks, GitHub Repository, 2026. [38]
- European Biosafety Framework, Richtlinien zu genetischer Sicherheit und Laborbetrieb in der EU, 2023–2025. [18]
Wenn autonome Labore zur strategischen Entscheidungsfrage werden
Die Kooperation von OpenAI und Ginkgo Bioworks zeigt, dass autonome KI gesteuerte Labore kein futuristisches Konzept mehr sind, sondern eine real umgesetzte Technologie mit messbarem wirtschaftlichem Effekt. Entscheidend ist nicht allein das eingesetzte Sprachmodell oder die Robotikplattform, sondern das zugrunde liegende Systemparadigma. Forschung wird nicht länger ausschließlich manuell geplant und durchgeführt, sondern als datengetriebener, geschlossener Optimierungskreislauf organisiert.
Für Entscheider verschiebt sich damit die Bewertungsgrundlage. Weniger relevant ist die Frage nach einzelnen Laborgeräten oder isolierten KI Funktionen. Im Mittelpunkt stehen Architektur, Validierung, Governance und Integrationsfähigkeit in bestehende Prozesse. Wer autonome Labore einsetzen möchte, muss Systemstabilität, Auditierbarkeit und regulatorische Konformität genauso berücksichtigen wie Effizienzgewinne und Kostensenkung.
Ob in der Wirkstoffentwicklung, im Enzymdesign, in der Materialforschung oder in der Prozessoptimierung – KI gesteuerte Closed Loop Systeme eröffnen neue Handlungsspielräume. Gleichzeitig steigen die Anforderungen an Sicherheitsmechanismen, ethische Kontrolle und organisatorische Anpassungsfähigkeit. Die zentrale Frage lautet daher nicht, ob autonome Labore kommen werden, sondern unter welchen Rahmenbedingungen sie verantwortungsvoll und skalierbar eingesetzt werden können.

Das Visoric Expertenteam: Ulrich Buckenlei und Nataliya Daniltseva im Austausch über autonome Systeme, industrielle KI und datengetriebene Forschungsarchitekturen
Quelle: VISORIC GmbH | München
An dieser Schnittstelle zwischen Technologie, Regulierung und strategischer Entscheidung arbeitet das Visoric Expertenteam in München. Im Fokus steht die analytische Einordnung komplexer KI und Automatisierungssysteme, die Bewertung von Chancen und Risiken sowie die verständliche Aufbereitung technologischer Entwicklungen für Management, Investoren und öffentliche Institutionen.
- Strategische Bewertung autonomer Laborsysteme und KI Forschungsarchitekturen
- Analyse von Sicherheits, Governance und regulatorischen Rahmenbedingungen
- Übersetzung komplexer KI und Automatisierungsprozesse für Entscheider
- Konzeption von Visualisierungen, Szenarien und technologiegestützten Entscheidungsmodellen
Wenn Sie prüfen möchten, welche Rolle autonome KI gesteuerte Labore in Ihrer Innovationsstrategie spielen können, bietet ein Austausch mit dem Visoric Expertenteam eine fundierte, unabhängige und praxisnahe Perspektive.
Kontaktpersonen: Nataliya Daniltseva (Projektleiterin) Adresse:
Ulrich Buckenlei (Kreativdirektor)
Mobil: +49 152 53532871
E-Mail: ulrich.buckenlei@visoric.com
Mobil: + 49 176 72805705
E-Mail: nataliya.daniltseva@visoric.com
VISORIC GmbH
Bayerstraße 13
D-80335 München